LLM Launcher
Stop reconstructing
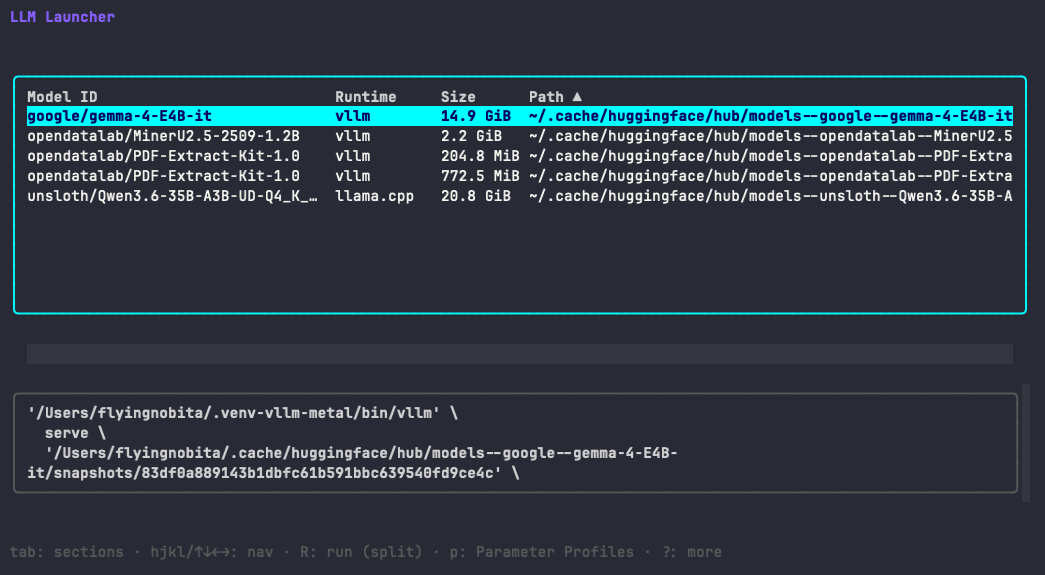
Stop reconstructing llama-server flags from shell history.
llml finds your local models, detects your runtimes, and launches them with a saved profile.
Pick a model, pick a profile, press R.
Works alongside llama.cpp, Ollama, vLLM, and KoboldCpp. Your backend stays exactly as it is.
Alternatives: Homebrew cask (macOS), Scoop/Winget (Windows), or Go. See Install instructions ↗